基于elasticsearch + logstash + kafka + filebeat的日志收集及近实时处理的集群介绍及搭建,基于rancher1.6平台。

elasticsearch + logstash + kafka + filebeat
简介
graph TD
A[logFile] -->|filebeat| B(kafka)
B --> C{logstash}
C -->|index1| D
C -->|index2| D
C -->|index3| D[Elasticsearch]
Elasticsearch是一个基于Lucene的搜索引擎。它提供了一个分布式,多租户 -能够全文搜索与发动机HTTP Web界面和无架构JSON文件。
Elasticsearch与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发。这三种产品设计用作集成解决方案,称为**“弹性堆栈”**(以前称为“ELK堆栈”)。
Elasticsearch可用于搜索各种文档。它提供可扩展的搜索,近实时搜索,并支持多租户。[2] “Elasticsearch是分布式的,这意味着索引可以分为多个分片,每个分片可以有零个或多个副本。每个节点托管一个或多个分片,并充当协调器,将操作委托给正确的分片。重新平衡和路由是自动完成的“。[2]相关数据通常存储在同一索引中,该索引由一个或多个主分片和零个或多个副本分片组成。创建索引后,无法更改主分片的数量
Elasticsearch
1
2
|
cluster status:
http://172.18.4.42:9200/_cluster/health
|

配置详解
data node
如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器
node.master: false
node.data: true
master node
如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器
node.master: true
node.data: false
client node
如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等
node.master: false
node.data: false
filebeat
从文件读取日志,通过tag进行标记,用于区分不同的日志,最后输出到kafka。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#输入
- type: log
paths:
- /var/log/amp/*.log
tags: ["amp-log"]
fields_under_root: true
document_type: amp-log
ignore_older: 24h
#输出
output.kafka:
hosts: ["kafka-broker-1:9092","kafka-broker-2:9092","kafka-broker-3:9092"]
topic: logstash
required_acks: 1
|
kafka
用于临时存储filebeat收集来的日志。
| key |
value |
| ADVERTISE_PUB_IP |
true |
| JVMFLAGS |
-Xmx2048m -Xms2048m |
| KAFKA_REPLICATION_FACTOR(副本数量) |
3 |
| KAFKA_LOG_RETENTION_HOURS(日志过期时间) |
24 |
| KAFKA_NUM_PARTITIONS(topic分区数量) |
10 |
| ZK_SERVICE |
ZK_SERVICE |

logstash
从kafka读取日志,使用正则过去日志信息,之后结构化日志,存入elasticsearch。
graph LR
A[INPUT] -->|kafka| B(filter)
B -->|tags| C{output}
C -->|index1| D
C -->|index2| D[Elasticsearch]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
# 从kafka读取日志
input {
# beats {
# port => "5044"
# }
kafka {
bootstrap_servers => "kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092"
topics => "logstash"
group_id => "logstash-group-01"
consumer_threads => 5
decorate_events => false
auto_offset_reset => "latest" # 从最新的偏移量开始消费
codec => "json"
}
# 结构化日志并清洗日志
filter {
if "amp-log" in [tags] {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{DATA:threadname}\] %{WORD:level}\s+%{DATA:topic}:%{GREEDYDATA:jsondata}" }
}
json {
source => "jsondata"
#target => "parsedJson"
remove_field=>["jsondata"]
}
date {
match => ["timestamp","YYYY-MM-dd HH:mm:ss.SSS"]
target => [ "@timestamp" ]
}
ruby {
code=>"event.set('index_day', event.get('@timestamp').time.localtime.strftime('%Y.%m.%d'))"
}
mutate {
remove_field => ["timestamp"]
remove_field => ["message"]
remove_field => ["threadname"]
}
if "success" in [topic] {
mutate { add_tag => [ "monitor-success" ] }
}
else if "repeat" in [topic] {
mutate { add_tag => [ "monitor-repeat" ] }
}
}
}
# 输出到elasticsearch
output {
if "monitor-success" in [tags] {
elasticsearch {
hosts => "elasticsearch:9200"
index => "amp-success-%{index_day}"
}
}
}
|
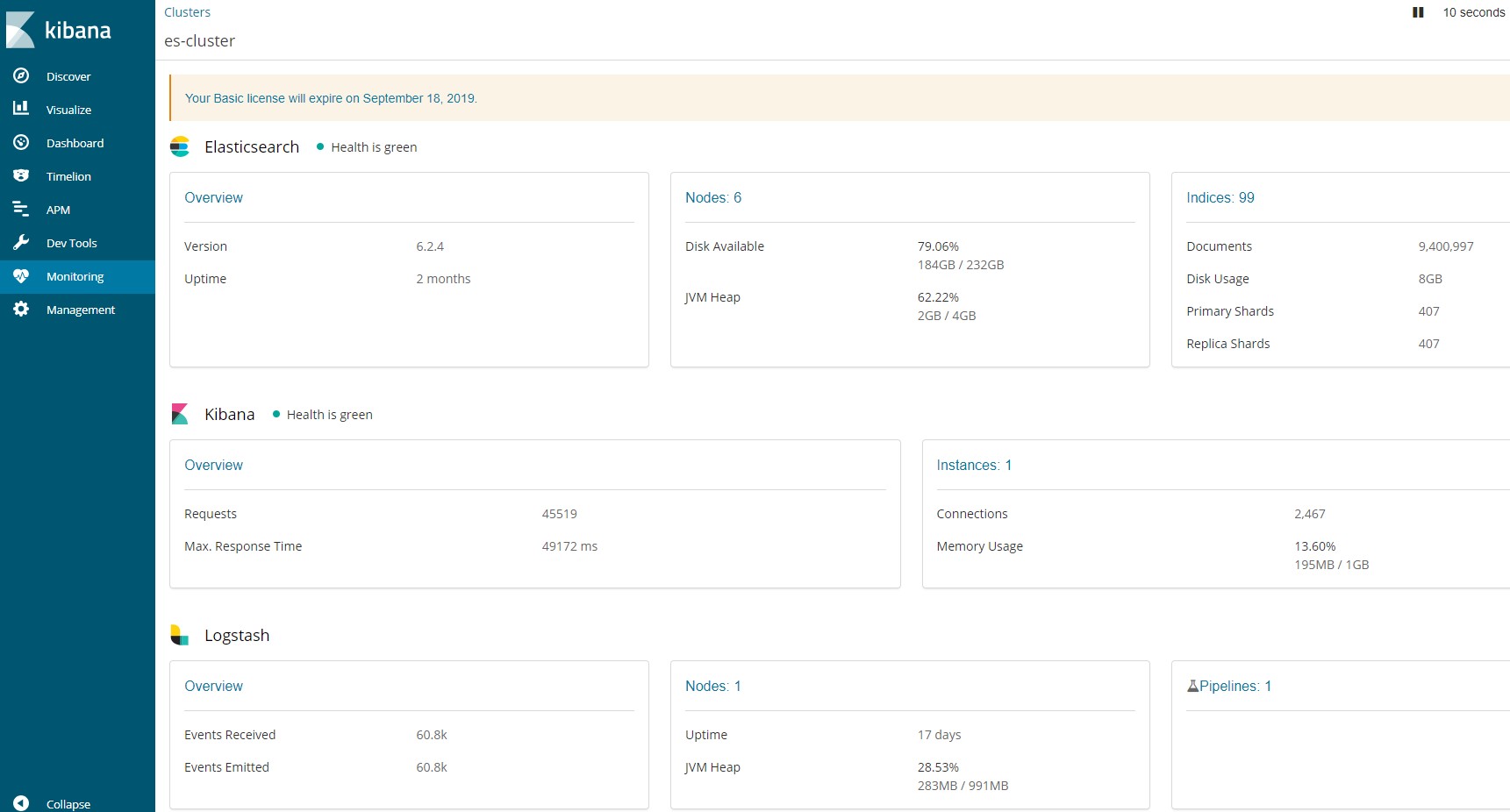
kibana
用于查询elasticsearch的数据,监控elasticsearch的监控状态
other
配置
1
2
3
4
5
6
7
8
9
|
// 索引写入缓存
indices.memory.index_buffer_size=20%
indices.memory.min_index_buffer_size=96m
// 存活超时时间
discovery.zen.fd.ping_timeout=120s
// 存活超时重试次数
discovery.zen.fd.ping_retries=6
// 节点间存活检测间隔
discovery.zen.fd.ping_interval=30s
|
索引模板配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 刷新间隔,merge线程数
PUT /_template/adv_logs
{
"index_patterns": ["aap-*", "amp-*"],
"order": 1,
"settings": {
"refresh_interval": "60s",
"merge": {
"scheduler": {
"max_thread_count": "1"
}
}
}
}
|
kafka
1
2
3
4
5
6
7
8
9
10
11
|
# alter partition
bin/kafka-topics.sh --zookeeper zk:2181 --alter --topic logstash --partitions 5
# list topics
bin/kafka-topics.sh --zookeeper zk:2181 --list
# describe topic
bin/kafka-topics.sh --zookeeper zk:2181 --topic logstash --describe
# describe consumer
bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group logstash-group-01 --describe
|